Data
The collection of raw facts and figures is called data. Data is an unprocessed entity which is given as an input to the model. Data on its own doesn’t have any meaning, it requires some amount of processing to make it meaningful.
For example: 560095 could be a population of a place, zip code, an amount, an ID, or anything else but Rs. 560095 clearly indicates monetary value.
Here, 560095 is data whereas Rs. 560095 is a piece of information as it provides definite meaning.
Knowledge is hidden potential patterns that provide meaningful insights which could help in decision-making.
Research is the systematic process of extracting the knowledge hidden in the data.
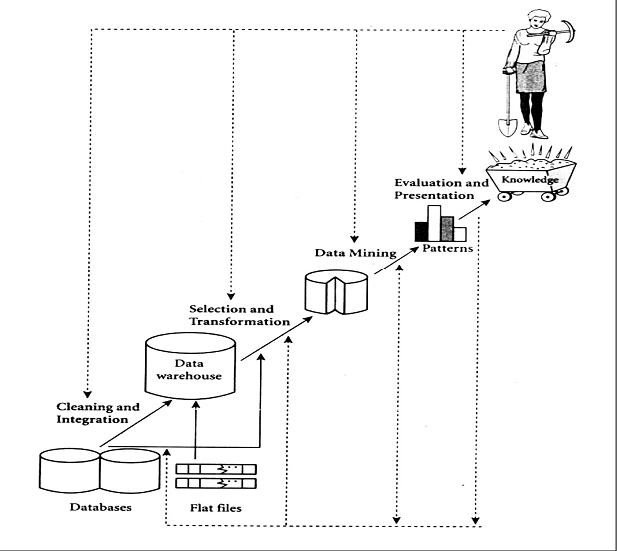
In order to extract hidden knowledge, we follow the KDD process.